Maximizing the value hidden within unstructured data
Executive summary
Capturing value from unstructured data is increasingly linked to competitive advantage. As the availability of unstructured data snowballs, the pressure to discover and then optimize its value increases.
Unstructured text data comes in both formal and informal formats. Formal sources include annual reports, research reports, news articles, company announcements, or transcripts of interviews. Informal sources can be emails, text messages, or social media posts. Each of these source types presents a unique set of challenges, including:
- What entities and entity types are in the body of text?
- Relationships between entities identified within the text?
- Which parts of the text are meaningful and relevant?
- How is the timing of the content recorded?
- How is data linked or integrated with other structured data assets?
The value
There are four clear benefits in improving an organization’s capability to integrate alternate data into its analysis. It leads to a better understanding of the levers and drivers of trading value:
- Get to the analysis sooner – Manage the complexity of training, monitoring and maintaining the entity mapping process to tag entities simply and efficiently. It minimizes the data wrangling by highly paid specialists to incorporate alternate data, often unstructured text.
- Optimized matching of entities across all data types and tables – Any unstructured text is quickly ingested and linked via knowledge bases, i.e. Entity Master and Security Master, to structured market data assets, like historical tick data.
- Maximize entity identification from any data source – Entity mapping models must be trained across an extensive corpus of documents, ensuring high levels of accuracy and maximizing company mentions.
- Enables seamless delivery of analysis-ready data to a range of on-premises and cloud-based environments to generate value quicker.
The principles involved
Developing a solution to the growing requirement for entity discovery and mapping had some underlying principles:
- Enable clients to discover more from data;
- Provide a cost-effective means to managing, storing and organizing data and derived outputs;
- Improve internal analytic efficiency, save time, deliver analysts and modelers quick access to data.
Data Science – the RoZetta difference
The Data Science Team has developed and refined our entity recognition engine, incorporating a custom Named Entity Recognition (NER) model.
Entity discovery is essential to ensure data is prepared and usable for analysis. It unlocks the potential for additional analysis, such as deriving sentiment, context, and related entity associations. These add depth to the analysis and modeling of financial markets data. All derived indexes are available as extensions in the RoZetta DataHex SaaS platform.
Identifying and tagging entities is required to link to a company’s Entity Knowledge Base. RoZetta records all the entities discovered, and their associated metadata, in an Entity Master. The Entity Master is a master database of all entities, and their aliases, discovered. The Entity Master also records the time and source of each mention of an entity. The Master Entity Table becomes a source of time-series data of entity discovery and each entity’s origins and context.
Locations, people, organizations, and incorporated entities are all examples of entities identified. For capital markets, one of the critical entities to identify is listed companies and any association with another entity, event, or relationship that may affect their value.
Listed entities can be linked using a proprietary concordance table of entity identifiers. Creating this link allows company mentions to be related to the associated market data, including tick data.
Alternative datasets evaluation & integration – signal identification
Alternate data, particularly unstructured data, is providing an increasing point of differentiation in advanced modeling to discover and apply Signal.
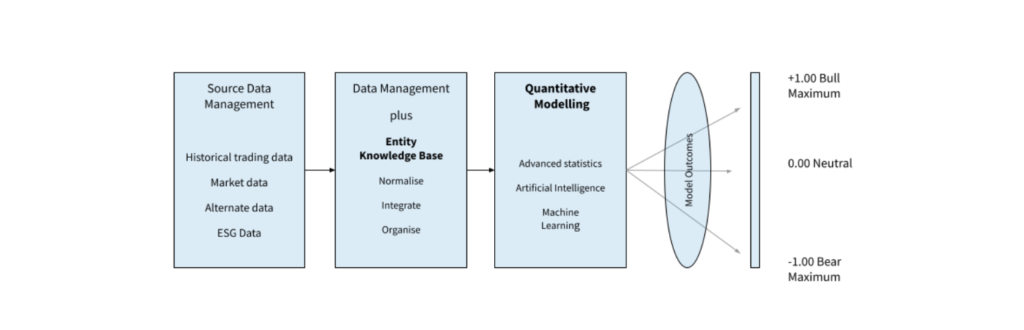
A trading Signal is a standardized value expressing how bullish or bearish a quantitative model is about individual financial instruments.
Input data includes historical trading data, market data, ESG data, alternate data (structured and unstructured), any data useful to assess an asset’s current or future value, or trading volume.
The key components of this process are the Entity Knowledge Base, to maximize the quality and incidence of matching entities across many data sources and Quantitative Modeling.
The entity discovery in unstructured data expands an organization’s Entity Knowledge Base and increases the entity attributes that can be passed through to the Quantitative Modeling function.
RoZetta Technology
RoZetta Technology unlocks the future by integrating its expertise in data science, cloud technology and managed services operations to transform high-volume, high-velocity structured and unstructured data into clear insights.
In a market driving for differentiation through data, organizations invest in expert applications and capability that deliver unique IP, and the opportunity for competitive advantage. To help clients remain nimble and innovative in this context while optimizing investment in technical infrastructure, RoZetta Technology provides a managed SaaS platform that offers a resilient and scalable data and technology solution.
More information
For a deeper understanding of the technical aspects of Entity Discovery RoZetta’s Data Science Team has published this document:
Contact us today about how we can accelerate your data journey and unlock the potential of your unstructured data assets.